Using RAG to power your marketing intelligence


Imagine you've just hired the most brilliant, creative, and experienced marketing strategist. They have an encyclopaedic knowledge of market trends, copywriting techniques, and strategic frameworks. There's just one problem: on their first day, they know absolutely nothing about your business.
They haven't read your brand guidelines, your past campaign performance reports, your customer personas, or your product documentation yet.
How do you get them up to speed? You could sit them in a room and lecture them for eight hours straight, trying to cram every piece of company knowledge into their memory. This, however, takes time and is not 100% effective...
Ideally, you would give them access to the company's shared drive—the library of your collective knowledge. You'd say, "Welcome aboard. Before you tackle any new project, consult this library to find the relevant documents. Use your expertise to act on what you find."
This is precisely what Retrieval-Augmented Generation (RAG) does for your AI systems.
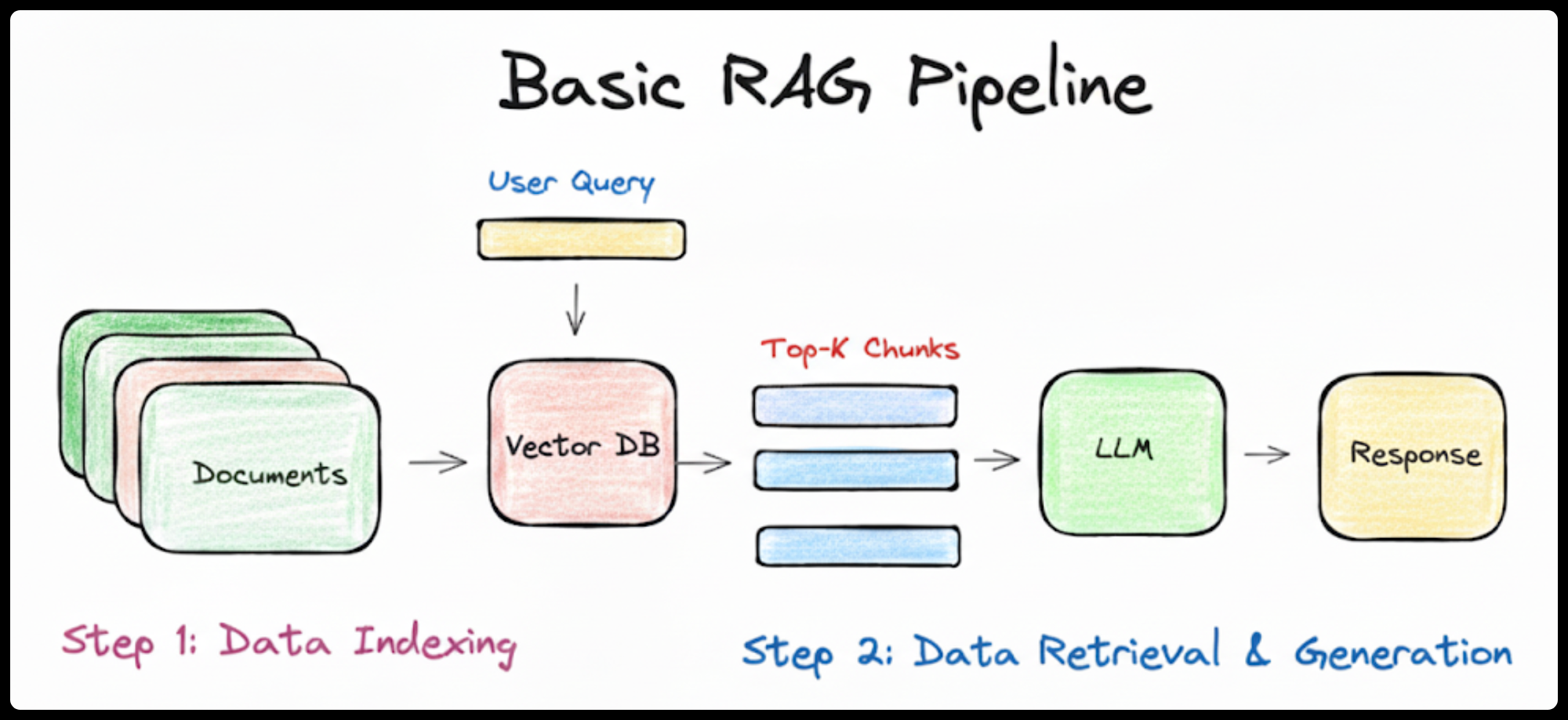
What is RAG in practice?
In a practical n8n workflow, a RAG system allows an AI Agent to answer a question like, "What were the key takeaways from our last product launch?"
Instead of answering from its generic LLM training data, the AI performs a clear sequence of tasks:
- It searches your company's digital library (your knowledge base).
- It instantly finds the relevant document—the post-launch performance report.
- It reads the key sections, like the executive summary.
- It uses that specific information to formulate a perfect, context-aware response.
If you combine RAG(s) with additional context sources, like your full data warehouse via BigQuery, you can create professional human-like assistants who can do a lot of great work for you, 24/7...
This article covers the core advantages of RAG, how it works, but also when a simpler solution might be a better fit.
The Core Advantages of RAG: Smarter Context and Deeper Knowledge
While Large Language Models (LLMs) are powerful, they face two key limitations in a business context: a finite "context window" (memory) and difficulty processing vast amounts of unstructured company data. RAG provides a strategic advantage by solving both issues.
It allows an AI to work with selective, relevant information to avoid overloading its memory, and crucially, it empowers the AI to draw insights from your entire library of unstructured content—from meeting notes to knowledge bases—turning it all into a reliable source of truth.
1. Selective Context for Efficiency and Speed
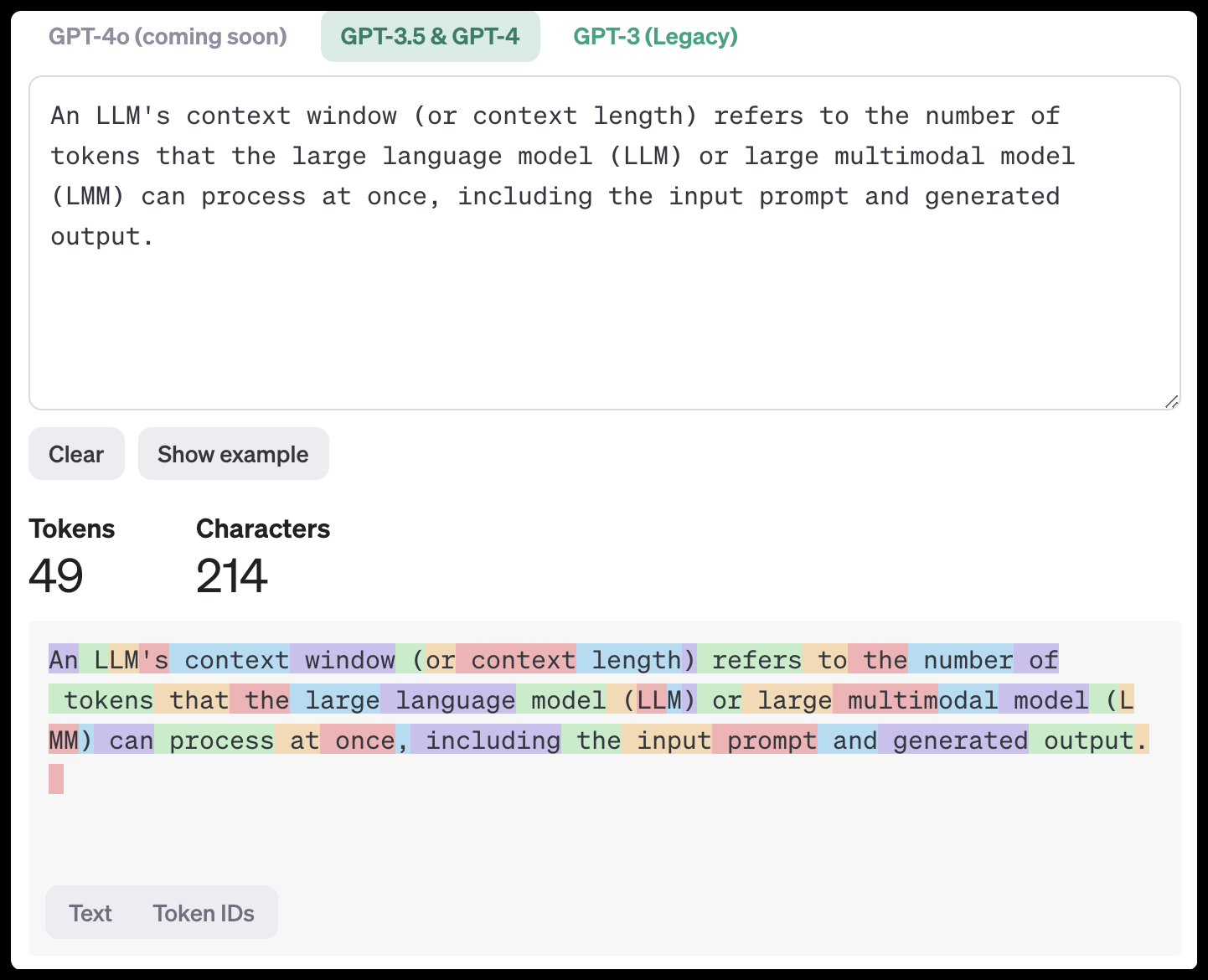
An LLM's context window can't fit your entire company's knowledge base. Instead of force-feeding the model massive documents in a single prompt, RAG enables selective context. By retrieving only the most relevant snippets for a specific task, it keeps the prompt clean and efficient. This has two major benefits:
- Cost-Efficiency: API calls are priced per token. Smaller, relevant prompts are far cheaper than repeatedly sending a 50-page document, which is critical for automated workflows making thousands of calls.
- Speed and Performance: Larger prompts take longer to process. RAG provides a focused context, leading to much faster response times and more reliable, performant automations.
2. Unlocking Insights from Unstructured Content
A key advantage of RAG is its ability to unlock insights from unstructured content. It allows you to connect an agent to raw meeting summaries, a complete Confluence knowledge base, or a year's worth of weekly business reviews, turning a chaotic library into a queryable asset.
However, this does not mean content structure is no longer important.
3. Grounded Knowledge for Accuracy and Scalability
Ultimately, RAG is the bridge that connects a generic LLM to your specific operational reality. By giving your AI agent access to company knowledge bases, databases, and performance reports, you transform it from a generalist into a specialized expert.
- Accuracy and Relevance: LLMs are notorious for "hallucinations" (making things up). RAG dramatically minimizes this risk by grounding the model in facts from your documents. Research also shows AI agents pay less attention to information buried in the middle of long prompts; RAG avoids this by providing only a few highly relevant snippets.
- Scalability and Maintenance: Imagine your company updates its brand guidelines. With a RAG system, you simply update that one document in your knowledge base, and the entire system is current. The alternative is manually finding and updating every static prompt across all your automations—an unscalable nightmare.
How It Works: The Three Parts of a RAG System
A RAG system can be broken down into three simple components:
- The Knowledge Base (Your Library): This is your curated collection of private documents: internal wikis, product documentation, past campaign reports, etc. This becomes your single source of truth.
- The Retriever (The Research Assistant): This is the intelligent search component. When you ask a question, the retriever instantly scans the knowledge base and finds the most relevant snippets of information using vector search, which understands semantic meaning.
- The Generator (The Expert Strategist): This is the LLM (e.g., GPT-5). It receives your question and the specific information found by the retriever. Its job is to synthesize this information and formulate a coherent, human-readable answer, "augmenting" its general knowledge with your provided facts.
When you don't need a RAG: Simpler alternatives
Before building a vector database, consider if a simpler approach will solve your problem.
- For small, static context files: Include the context directly in the system prompt. Modern LLMs have vast context windows, often large enough to fit dozens of pages of text. If your agent only needs to reference a single policy document, a product one-pager, or a specific set of guidelines, pasting that text into the prompt is the simplest solution. A RAG system is overkill when the entire knowledge base can fit into the model's immediate memory.
- For agent instructions (static rules): Use detailed system instructions. If you just need the AI to always write in a specific, formal tone or follow a certain output format, a well-crafted prompt is far more efficient.
- For real-time, singular data points: Use tools or API calls. If an agent needs to know the current status of a specific customer, have it call your CRM's API. A RAG is for a broad knowledge base, not a single transactional lookup.
| Situation | Recommended Solution |
|---|---|
| AI needs to write with our brand voice & tone. | Detailed system prompt. |
| AI needs to answer questions about our 1,500 product spec sheets. | RAG |
| AI needs to check the current stock of a single product. | Tool / API Call |
| AI needs to summarize the last 5 years of customer feedback. | RAG |
| AI needs to summarize a 20 page strategy doc. | System prompt with file upload |
Practical considerations for marketers
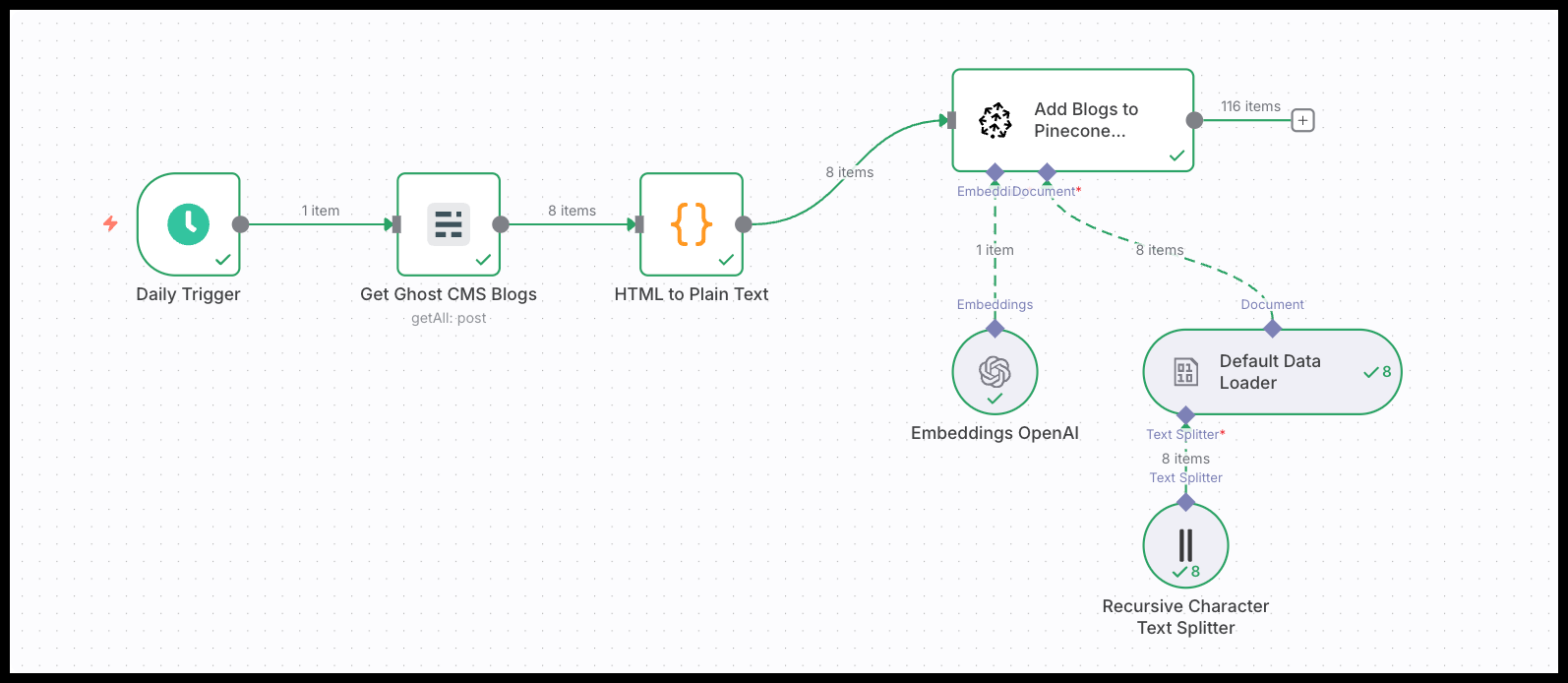
Setting up a RAG system isn't without effort. It involves costs for the embedding process (which usually happens once per document) and for hosting the vector database. However, the ecosystem is rapidly maturing. Options range from dedicated, high-performance services like Pinecone to integrated solutions like Supabase's pgvector, which can be a cost-effective way to get started by adding vector capabilities to a standard database.
The key is to know that while there's a setup process, the long-term benefits in cost, speed, and accuracy far outweigh the initial investment.
Your AI, your expert...
Retrieval-Augmented Generation elevates your AI from a general-purpose tool to a specialized expert with deep, persistent knowledge of your specific business context. While it requires more setup than a simple prompt, a RAG system unlocks the ability to build truly intelligent AI systems that can automate complex analysis and decision-making with a level of accuracy and relevance that would otherwise be impossible. It's the key to making AI work for your business, not just a business.
In this article, we covered the "what" and "why" of Retrieval-Augmented Generation (RAG). Now, it's time to get practical and build one.



